






こんにちは、ポケモントレーナーの浅海です。最近になってようやく「げんきのかたまり」を使える様になりました。
さて近頃AWS Lambdaというサービスの名前を聞く機会が多くあったので、どのようなものなのか調べたいと思っていましたが、ついに機会ができたので実際に使ってみました。
Lambdaとは
Lambdaがどのようなサービスなのかどうかは、AWS公式のドキュメントに説明が書かれています。その冒頭部分を引用します。
AWS Lambda は、コードを AWS Lambda にアップロードすると、サービスが AWS インフラストラクチャを使用してコードの実行を代行するコンピューティングサービスです。コードをアップロードして、Lambda 関数と呼ばれる関数を作成することで、AWS Lambda がコードを実行するサーバーのプロビジョニングおよび管理を行います。AWS Lambda は次のように使用できます。
・・・・?
インフラ面で造詣の深い方であればこれを読んで理解できるのだと思いますが、初心者の自分には理解不能でした。なんか全体的にAWSの公式ドキュメントは横文字が多くてクラクラしてしまいます。
ですが「自分で書いたコードを実行できる環境だ」というざっくりとしたことはなんとか理解できたので、単純なコードを書いてLambdaで実行してみようと思います。
AWS Lambdaのマネジメントコンソールでは「Lambda関数」という単位で物事を定義していくことになります。
本記事では、LambdaでTwitterを検索してSlackに通知するLambda関数を実装するのですが、これを作ろうとした動機として、弊社はDocBaseというサービスを開発、運営していることがあります。
DocBaseユーザ様の声をいち早く拾うために、Twitterで「DocBase」を検索してサポートに役立てていますが、このTwitterの検索はいつも手動でやっているので手間がかかります。その検索作業を自動化するために、「DocBase」というtweetをTwitterから取得して、Slackに通知するLambda関数をJavaScriptで作りました。
下準備
AWS Lambdaを触る前に、今回作成するモジュールに必要な次の3つを用意します。
- 通知先Slackチャンネルのwebhook URL
- Twitter検索APIを使う時に使うTwitterアプリのキー
- 専用のIAMロール
- Lambda関数は指定したIAMロールの権限で実行されるため、AWSの他サービスと連携する場合は、その権限があるIAMロールを作成する必要があります。
今回はデータの保存場所としてS3を使うので、特定のS3バケットの操作権限のみ持ったIAMロールを作成しました。
- Lambda関数は指定したIAMロールの権限で実行されるため、AWSの他サービスと連携する場合は、その権限があるIAMロールを作成する必要があります。
では準備もできたところで、順を追ってLambda関数を作成していきます。
1. AWS Management Console
AWS Lambdaのマネジメントコンソールを開くと、「Create a Lambda function」というボタンがあるので押してみます。
2. Select blueprint
blueprintとは、言い換えるのであればレシピやテンプレート、雛形に相当します。
画面には50種以上のblueprintが表示されていますが、今回はnodeモジュールを実行するbrueprintであるnode-execを選択します。
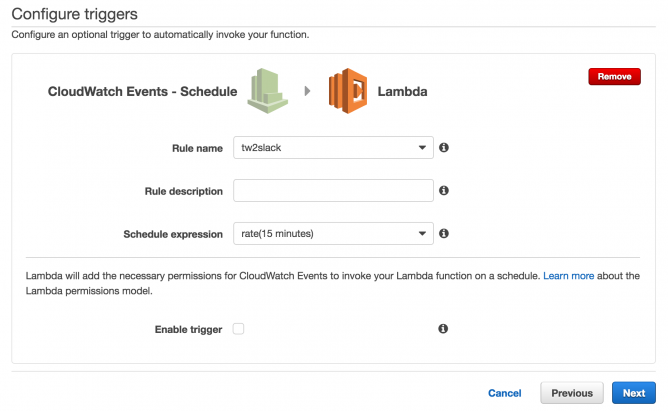
3. Configure triggers
この画面では、何を引き金(trigger)にしてLambda関数が実行されるのかを指定することができます。
9つもありますが、今回は定期的に実行するLambda関数なので、cron形式で定期実行の設定を書くことができる「CloudWatch Events – Schedule」を指定します。
この画面の下の方にある「Enable trigger」のチェックボックスをチェックしてしまうと定期実行が開始されてしまうので、動作テストが完了するまではチェックしないでおきます。
4. Configure function
画面内のテキストフォームには最初からちょっとしたコードが書かれていますが、自分で書いたJavaScriptのコードは後ほどZIPでアップロードするので、必須項目であるNameとIAM roleだけを設定して完了とします。
これで無事にLambda関数の定義が終わりました。
Slackに通知
まずはLambdaからSlackに単純なメッセージを送信してみます。
Lambda関数の設定時にnode-execを選択したことからわかるように、開発にはnodeを使います。自分の開発マシン上で適当なディレクトリを用意し、npm initして、そこで開発を始めます。
Slack通知にはslack-nodeというモジュールを使うのでインストールします。
npm install slack-node --saveLambdaの設定では、Handlerという項目の初期値として「index.handler」が設定されています。
これは「実行時はindex.jsのmodule.handlerを実行する」という状態で設定されているとういことなので、index.jsを用意し、module.handlerという関数を用意します。
次のスクリプトは、Slackの指定チャンネルに「Hello World!!」とだけ通知します。ちなみにnode-execを選択時のnode.jsのバーションは初期値でnode.js4.3のため、ES6が割と使えます。せっかくなので使っていきます。
※ ここではSlackのwebhook URLを直接記述していますが、これを隠したい場合にはKMSを使う方法があります。
IAMのマネジメントコンソールから暗号化キーを作成し、コード上にはその暗号化キーでwebhook URLを暗号化したものを記述することになります。
// index.js
'use strict'
var Slack = require('slack-node')
var slack = new Slack();
slack.setWebhook('https://hooks.slack.com/services/xxxxxxxxx/xxxxxxxxx/xxxxxxxxxxxxxxxxxxxxxxxx')
exports.handler = (event, context, callback) => {
slack.webhook({
username: 'Lambda',
text: 'Hello World!!'
}, (error, response) => {
context.done()
})
}
アップロード
AWS LambdaのマネジメントコンソールでFunctionsの画面を見ると、先程作成したLambda関数が追加されています。
テキストフォームに表示されているサンプルコードは使わないので、「Code entry type」をUpload a .ZIP fileに変えて、ZIPをアップロードするようにします。
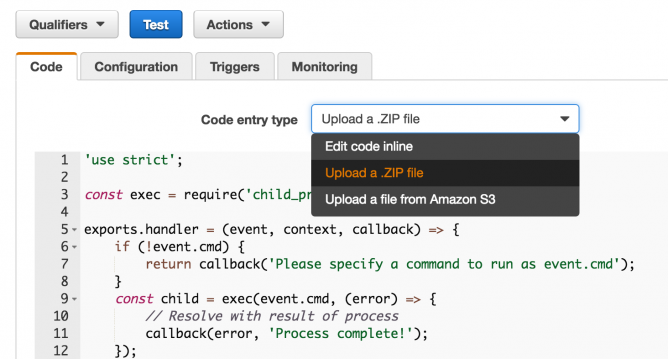
先程作成したindex.jsと、nodeモジュールのインストール先となっているnode_modulesをまとめてZIPにしてアップロードします。
node_modulesをZIPに含めるのを忘れると動きませんので注意してください。
ファイルを選択したら「Save and test」ボタンを押して実行してみます。
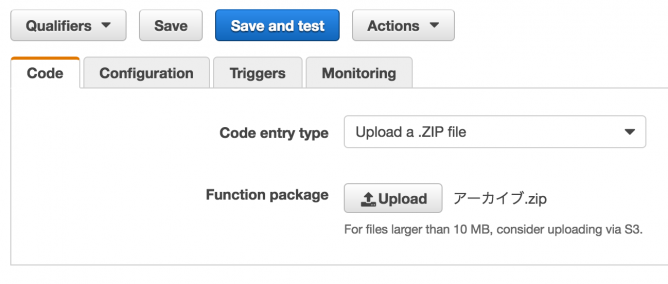
テストを実行するときに最初の1回はパラメータの設定が表示されますが、今回作っているLambda関数はパラメータ扱わないためそのまま「Save and Test」を押して実行に進んで問題ありません。
実行後、Slackに「Hello World」と通知されたはずです。
Twitter検索
Twitter検索はtwitterというnodeモジュールをインストールして使うので苦労はありません。
npm install twitter --save次のコードは、Twitterの検索結果を単純にSlackに投げるコードです。
TwitterのAPIを利用するために用意するキーも、KMSを使用して暗号化したものを使用するのがよいでしょう。
var Twitter = require('twitter')
var Slack = require('slack-node')
var slack = new Slack();
slack.setWebhook('https://hooks.slack.com/services/xxxxxxxxx/xxxxxxxxx/xxxxxxxxxxxxxxxxxxxxxxxx')
var twitterClient = new Twitter({
consumer_key: '@@@@@@',
consumer_secret: '#####',
access_token_key: '$$$$$$',
access_token_secret: '%%%%%%%%'
})
exports.handler = (event, context, callback) => {
twitterClient.get('search/tweets', {q: 'docbase lang:ja exclude:retweets'}, (error, tweets, response) => {
let tweetsCount = tweets.statuses.length
let noticed = 0
for(let i=tweetsCount-1; i>=0; i--){
let tweet = tweets.statuses[i]
slack.webhook({
username: `@${tweet.user.screen_name}`,
text: tweet.text,
icon_emoji: tweet.user.profile_image_url_https
}, (error, response) => {
noticed++
if(noticed == tweetsCount) {
context.done()
}
})
}
})
}
データの保存
ここまででtweetをSlackに通知できるようになりました。ですがこのままでは実行する度に同じtweetをSlackに通知してしまう可能性があります。
これを解消するために、最後に取得したtweetのIDを保存しておき、そのIDより大きいIDを持つtweetのみをSlackに通知するようにしたいと思います。
Lambdaから扱えるデータの保存先としてはRDS、S3、ElasticCache、DynamoDBなどが考えられますが、今回のデータはtweetのidを1つだけ保存できれば良いので、RDSやElasticCacheなどはコストに見合いませんし、DynamoDBは扱ったことがありません。そのため、S3にテキストファイルとして保存するようにします。
Lambda関数でs3を扱うために、aws-sdkというnodeモジュールを使用するのでインストールします。実はaws-sdkは標準で入っているため、アップロードするZIPに含めなくても動きますが、手順を揃えるために入れています。
npm install aws-sdkLambda関数に紐付けたIAMロールには、指定したバケットに読み書きできる権限を持たせておく必要があります。
tweetのIDは、既に普通の整数型が扱いきれるような桁数では無いため文字列のまま比較をしています。
'use strict'
var aws = require('aws-sdk')
var Twitter = require('twitter')
var Slack = require('slack-node')
var slack = new Slack();
slack.setWebhook('https://hooks.slack.com/services/xxxxxxxxx/xxxxxxxxx/xxxxxxxxxxxxxxxxxxxxxxxx')
var twitterClient = new Twitter({
consumer_key: '@@@@@@',
consumer_secret: '#####',
access_token_key: '$$$$$$',
access_token_secret: '%%%%%%%%'
})
aws.config.region = 'ap-northeast-1';
var s3 = new aws.S3({ apiVersion: '2006-03-01' });
exports.handler = (event, context, callback) => {
s3.getObject({
Bucket: 'tw2slack',
Key: 'max_tweet_id_test'
}, (err, data) => {
if(err) {
context.done()
return
}
onGetS3Object(context, data.Body.toString())
})
}
var onGetS3Object = (context, maxTweetId) => {
console.log(`maxTweetId: ${maxTweetId}`)
let attachments = []
twitterClient.get('search/tweets', {q: 'docbase lang:ja exclude:retweets'}, (err, tweets, response) => {
if(err) {
context.done()
return
}
onGetTweets(context, maxTweetId, tweets)
})
}
var onGetTweets = (context, maxTweetId, tweets) => {
let nextMaxTweetId = maxTweetId
let noticed = 0
for(let i=tweets.statuses.length-1; i>=0; i--) {
let tweet = tweets.statuses[i]
if(tweet.id_str.length < maxTweetId.length || tweet.id_str.length == maxTweetId.length && tweet.id_str <= maxTweetId) {
continue
}
nextMaxTweetId = tweet.id_str
slack.webhook({
username: `@${tweet.user.screen_name}`,
text: tweet.text,
icon_emoji: tweet.user.profile_image_url_https
}, (err, response) => {
if(++noticed < tweets.statuses.length) {
return
}
console.log(`nextMaxTweetId: ${nextMaxTweetId}`)
s3.putObject({
Bucket: 'tw2slack',
Key: 'max_tweet_id',
ContentType: 'text/plain',
Body: nextMaxTweetId
}, (err, data) => {
context.done()
})
})
}
}
動作を確認して問題ないようであれば、LambdaのマネジメントコンソールにあるTriggersタブからCloudWatch Events - ScheduleをEnableにします。
すると、指定したcronの間隔で定期実行されるようになります。
モジュールのバージョン
これまでに出てきたとおり、slack-node、twitter、aws-sdkの3つのnpmモジュールを使いました。package.jsonのdependenciesは次の状態で実装しています。
/* package.json
・
・略
・ */
"dependencies": {
"aws-sdk": "^2.5.5",
"slack-node": "^0.2.0",
"twitter": "^1.4.0"
}
}
料金体系
https://aws.amazon.com/jp/lambda/pricing/
今回のLambda関数では、メモリを最小128MB、15分毎の実行で運用しています。メモリが128MBの場合、100万リクエストと320万秒が毎月の無料枠になるため、余裕で無料運用できます。
AWS Lambdaの可能性
Lambdaでやるようなことは、サーバが1つあれば実現できることが多いかとは思いますが、EC2インスタンスを1つ建てるよりも少ないコードかつ低コストで実現できることができます。
Lambda関数に使用できる言語は今回使ったNode.jsの他に、JAVA,Pythonがあります。blueprintは50種以上、トリガーとして指定できるAWSサービスが9種類もあり、さらにこれらはいくらでもカスタマイズできるので、やれることはかなり多いようです。
気になるのは、動作確認のためにはいちいちZIPをアップロードする点ですが、codeshipやServerlessのようにそれを改善する方法もあるようなので試してみたいと思います。
プログラムが書けない人でも、IFTTTのレシピを使えば本記事で作ったLamda関数を簡単に作ることが出来ます。
そんな便利なAWS Lambdaを、ぜひ皆さんも使ってみて下さい。
宣伝
DocBaseとは
情報共有を活発にし、チームを育てるをコンセプトにした情報共有サービスです。柔軟な権限設定と使いやすさ、社内の人も社外の人も全員を招待できるから、さまざまな人やツールに散らばっていた情報を一元化できます。積極的な情報共有と業務の効率化を実現し、チームの成長を促します。
詳しくはこちらから。
DocBase


このエントリーに対するコメント
日本語が含まれない投稿は無視されますのでご注意ください。(スパム対策)
- トラックバック

最近の記事
人気の記事




「いいね!」で応援よろしくお願いします!